Introduction to turbulence/Statistical analysis
From CFD-Wiki
Contents |
Foreword
Much of the study of turbulence requires statistics and stochastic processes, simply because the instanteous motions are too complicated to understand. This should not be taken to mean that the govering equations (usually the Navier-Stokes equations) are stochastic. Even simple non-linear equations can have deterministic solutions that look random. In other words, even though the solutions for a given set of initial and boundary conditions can be perfectly repeatable and predictable at a given time and point in space, it may be impossible to guess from the information at one point or time how it will behave at another (at least without solving the equations). Moreover, a slight change in the intial or boundary conditions may cause large changes in the solution at a given time and location; in particular, changes that we could not have anticipated.
Here will be introduced the simple idea of the ensemble average
Most of the statistical analyses of turbulent flows are based on the idea of an ensemble average in one form or another. In some ways this is rather inconvenient, since it will be obvious from the definitions that it is impossible to ever really measure such a quantity. Therefore we will spendlast part of this chapter talking about how the kind of averages we can compute from data correspond to the hypotetical ensemble average we wish we could have measured. In later chapters we shall introduce more statistical concepts as we require them. But the concepts of this chapter will be all we need to begin a discussion of the averaged equations of motion in Chapter 3
The ensemble and Ensemble Average
The mean or ensemble average
The concept of an ensebmble average is based upon the existence of independent statistical event. For example, consider a number of inviduals who are simultaneously flipping unbiased coins. If a value of one is assigned to a head and the value of zero to a tail, then the average of the numbers generated is defined as
|
| (2) |

where our 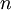 th flip is denoted as
th flip is denoted as  and
and 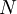 is the total number of flips.
is the total number of flips.
Now if all the coins are the same, it doesn't really matter whether we flip one coin times, or coins a single time. The key is that they must all be independent events - meaning the probability of achieving a head or tail in a given flip must be completely independent of what happens in all the other flips. Obviously we can't just flip one coin and count it times; these cleary would not be independent events
Unless you had a very unusual experimental result, you probably noticed that the value of the 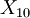 's was also a random variable and differed from ensemble to ensemble. Also the greater the number of flips in the ensemle, thecloser you got to
's was also a random variable and differed from ensemble to ensemble. Also the greater the number of flips in the ensemle, thecloser you got to  . Obviously the bigger , the less fluctuation there is in
. Obviously the bigger , the less fluctuation there is in 
Now imagine that we are trying to establish the nature of a random variable 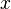 . The th realization of is denoted as . The ensemble average of is denoted as
. The th realization of is denoted as . The ensemble average of is denoted as 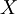 (or
(or 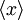 ), and is defined as
), and is defined as
|
| (2) |
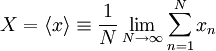
Obviously it is impossible to obtain the ensemble average experimentally, since we can never an infinite number of independent realizations. The most we can ever obtain is the ariphmetic mean for the number of realizations we have. For this reason the arithmetic mean can also referred to as the estimator for the true mean ensemble average.
Even though the true mean (or ensemble average) is unobtainable, nonetheless, the idea is still very useful. Most importantly,we can almost always be sure the ensemble average exists, even if we can only estimate what it really is. The fact of its existence, however, does not always mean that it is easy to obtain in practice. All the theoretical deductions in this course will use this ensemble average. Obviously this will mean we have to account for these "statistical differenced" between true means and estimates when comparing our theoretical results to actual measurements or computations.
In general, the couldbe realizations of any random variable. The defined by equation 2.2 representsthe ensemble average of it. The quantity is sometimes referred to as the expacted value of the random variables , or even simple its mean.
For example, the velocity vector at a given point in space and time 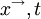 , in a given turbulent flow can be considered to be a random variable, say
, in a given turbulent flow can be considered to be a random variable, say 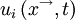 . If there were a large number of identical experiments so that the
. If there were a large number of identical experiments so that the 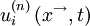 in each of them were identically distributed, then the ensemble average of would be given by
in each of them were identically distributed, then the ensemble average of would be given by
|
| (2) |
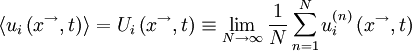
Note that this ensemble average, 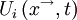 , will , in general, vary with independent variables
, will , in general, vary with independent variables 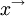 and
and 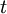 . It will be seen later, that under certain conditions the ensemble average is the same as the average wich would be generated by averaging in time. Even when a time average is not meaningful, however, the ensemble average can still be defined; e.g., as in non-stationary or periodic flow. Only ensemble averages will be used in the development of the turbulence equations here unless otherwise stated.
. It will be seen later, that under certain conditions the ensemble average is the same as the average wich would be generated by averaging in time. Even when a time average is not meaningful, however, the ensemble average can still be defined; e.g., as in non-stationary or periodic flow. Only ensemble averages will be used in the development of the turbulence equations here unless otherwise stated.
Fluctuations about the mean
It is often important to know how a random variable is distributed about the mean. For example, figure 2.1 illustrates portions of two random functions of time which have identical means, but are obviuosly members of different ensembles since the amplitudes of their fluctuations are not diswtributed the same. it is possible to distinguish between them by examining the statistical properties of the fluctuations about the mean (or simply the fluctuations) defined by:
|
| (2) |
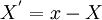
It is easy to see that the average of the fluctuation is zero, i.e.,
|
| (2) |
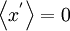
On the other hand, the ensemble average of the square of the fluctuation is not zero. In fact, it is such an important statistical measure we give it a special name, the variance, and represent it symbolically by either ![var \left[ x \right]](/W/images/math/d/1/c/d1c43f684f5952bdd96132dfa2ada32a.png) or
or 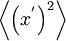 The variance is defined as
The variance is defined as
|
| (2) |
![var \left[ x \right] \equiv \left\langle \left( x^{'} \right) ^{2} \right\rangle = \left\langle \left[ x - X \right]^{2} \right\rangle](/W/images/math/8/a/0/8a0122b6bb2645f2dbd986a50dc0d485.png)
|
| (2) |
![= \lim_{N\rightarrow \infty} \frac{1}{N} \sum^{N}_{n=1} \left[ x_{n} - X \right]^{2}](/W/images/math/3/b/d/3bd51fe3a21e39adbfe74ee96de9f7b0.png)